Solving business problems with graphs
“Every Business Problem is a Graph Problem.”
Dr Daniel Alexander Smith
Head of Data Engineering, 6point6
All organisations find it difficult to fully describe their organisation in data. Businesses have spent billions trying to create considered data views of their organisations. One of the most common pitfalls is underestimating the number of human-driven connections between data which have never been captured digitally. For example, a manager of a manufacturing facility knows the financial controller and they share an understanding of how two different data sets relate to each other, and where the connections lie. Their workflow has never required these connections to be formalised, and won’t even necessarily benefit from doing so. However, the organisation’s attempt to make a considered view typically involves introducing new software to modify workflows to expose the connections. Such an approach requires buy-in from multiple levels within the organisation, and a protracted implementation period, and ensuing dip in productivity. With graph approaches these latent connections can be encoded as a view externally to the system-of-record data silos, without enduring a full re-integration exercise.
Considered Views Across The Business
Graph databases and graph abstractions enable views to be curated over multiple and varied data sources. There is rarely a single graph “view of the world” and the aim of the exercise is not therefore to create a monolith master database, but to curate and mark-up the connections between business data silos as metadata.
This metadata can then be used by graph software to present the view using APIs, query interfaces and rich interactive visualisations. This approach fundamentally aligns with modern data platform architectures of decentralised microservices that communicate using REST APIs, a design which developed to avoid creation of tightly-coupled monolithic services. As such, it is also deliverable using modern agile methods and maintainable using DevOps and DataOps team methodologies.
Types of Problems that Graphs Solve
The bold statement that every business problem is a graph problem is rooted in fact. Most business problems are about bringing the right resources together in order to fix a problem. A graph is able to blend various datasets into a structure that enables the ability to reveal connections.
- Fraud Detection: Business events and customer data, such as new accounts, loan applications and credit card transactions can be modelled in a graph in order to detect fraud. By looking for suspicious patterns of customer activity metadata and cross-referencing with previously identified fraud, we can flag up potential fraud that may be ongoing.
- 360-Degree Customer View: A compelling use of graph databases is in integrating data from across a business’s data silos to generate a considered view of the overall landscape. One of the most immediate uses of such a view is to enable a so-called “360-degree customer view”, to allow all data known about a customer to be integrated, from data silos across an organisation.
- Network Mapping: Infrastructure mapping and inventory is a natural fit for representation as a graph. In particular when mapping relationships between connected physical/virtual hardware and the services that they support. A graph of the relationships between infrastructure components not only enables interactive visualisations of the network estate but also network tracing algorithms to walk the graph, identifying bottlenecks, evaluating latency and performing dependency management.
Choosing a Graph Database
A consideration when designing a graph solution is which technology to use to model the data. Specifically, there are two well-supported graph database operating modes:
- Labelled Property Graphs (LPGs)
- Resource Description Framework (RDF) Graphs
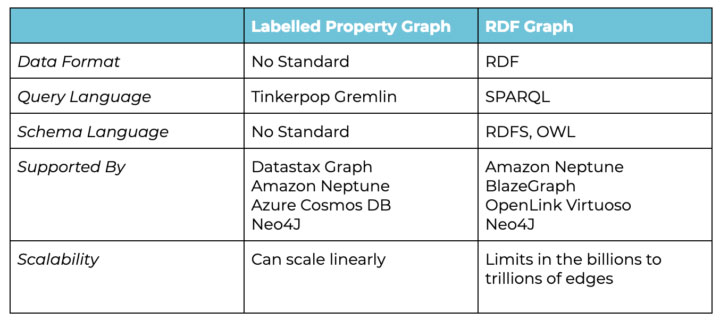
They are similar, in that they represent data using nodes and edges to form graphs, but they have different considerations of use, complexity, and features. The most important differences are in the formats used to describe the data, and the languages used to query the graph:
Graph Data Representation
When using RDF graphs, the data model is declared using OWL, the Web Ontology Language, where data classes and properties are identified with URIs. In a Labelled Property Graph, there is no formal specification for the taxonomy/schema of the data, and typically short strings are used instead. The important difference is that references to OWL ontologies are globally referenceable and therefore shared among data publishers. For example, FIBO, the Financial Industry Business Ontology, is used by publishers in the finance industry such as Bloomberg and Thomson Reuters. When data from each publisher lists an entity as being a “FIBO Student Loan” (specifically, by using the following URL) there is a shared and documented understanding of what that means (i.e., a Student Loan in this case). It also means that a graph loaded with data from Bloomberg and Thomson Reuters can be queried for a FIBO Student Loan, and data from both publishers will be returned and considered in the query. Thus, data from multiple sources is seamlessly integrated into a single graph.
Achieving Scale
There are multiple models employed by graph databases to achieve scale, in terms of how much data can be loaded, loading speed, query time, reads per second, writes per second and so on. The scaling model also has a bearing on whether the database scales vertically (i.e. by increasing the size of the server), or horizontally (i.e. by increasing the number of servers). Typically vertical scaling hits physical limits earlier and is more expensive as the limits are approached, whereas horizontal scaling tends to have much larger limits and uses cheaper servers. This difference is a major consideration among choice of graph database software for big data architects. Two of the most used graph databases in production today are Amazon Neptune and Datastax Graph. Amazon Neptune scales vertically using a single master node and up to 15 read replicas, whereas Datastax Graph scales horizontally using its underlying Cassandra database technology and therefore can scale linearly to very high numbers of nodes (Apple is said to run over 75,000 nodes, achieving millions of read and writes per second).
IMPLEMENTATION TIPS
Know the Use Cases
Estimate the size of the graph based on the graph data model chosen. Identify the current read and write patterns of enterprise data, and extrapolate future usage increases. Use these measurements to ensure your chosen graph database will scale to your needs, by evaluating the limits of each graph database.
Design for Scale-Up
Once you get going with graphs, you will want to experiment with connecting more data sources together and performing queries across them – design your data pipelines to handle large data streams to prevent roadblocks in future.
Formalise the Data Model
It may be tempting to deal with formalities in future, but our experience is that you get the most from the graph process by using rich expressive data models early-on.
Ensure you Record Data Provenance
The lineage of data, as it is moved through data systems, processed and combined can be recorded as provenance metadata and included in the graph. Ensuring complete data provenance is essential for data regulations now and in the future.
Investigate RBAC within the Graph
Using role-based access control using ontologies within a graph is a well-trodden path to elegantly integrate data security at a graph level; investigate whether this works within your security architecture.
Research Business Ontologies
Many ontologies have been freely published that cover different business areas in granular detail, research the areas that your data covers to find pre-made ontologies to model your business as a graph.
At 6point6 we have in-depth experience delivering graph database solutions for our clients, and maintaining them using our DataOps methodology.
For more information please contact us.
Written by Dr. Daniel Alexander Smith, Lead Big Data Architect