Common software vulnerabilities, Part I: heap overflows
Introduction
One of the most widely taught software exploits is a stack buffer overflow, and although they’re great for learning they aren’t very applicable in the real world. Most modern security vulnerabilities that make the headlines involve exploiting heap corruption or use after frees. For more on vulnerability trends, see this presentation from Microsoft.
The heap is potentially large and complex, and so there are different types of vulnerabilities: there are heap overflows, use after free and double free vulnerabilities. In these series of blogs I’ll cover all the previously mentioned heap vulnerabilities, starting off with heap overflows.
Heap vs. Stack
Before I dive into some code, let’s have a brief comparison between the stack and the heap. When a program is run, both the heap and stack are created and stored in RAM, but they have some important differences. For starters, the stack is used for static memory allocation, whereas the heap is used for dynamic memory allocation. An important difference is the stack is normally used for lightweight data for fast access, such as local variables. The heap normally holds objects and data structures, these pieces of data may be slower to access, however it’s useful if you do not know the exact size of the piece of data you want to set. For a more in depth article discussing their differences and what they are, I’d recommend reading this article.
Example C Code
Let’s look at some example code:
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <stdio.h>
#include <sys/types.h>
struct data {
char name[64];
};
struct fp {
int (*fp)();
};
void winner()
{
printf("level passed\n");
}
void nowinner()
{
printf("level has not been passed\n");
}
int main(int argc, char **argv)
{
struct data *d;
struct fp *f;
d = malloc(sizeof(struct data));
f = malloc(sizeof(struct fp));
f->fp = nowinner;
printf("data is at %p, fp is at %p\n", d, f);
strcpy(d->name, argv[1]);
f->fp();
}
This code was taken from exploit-exercises. This challenge is “protostar heap0”.
First, let’s start by walking through the code. I find it helps when you first just read the code and understand it, without looking for vulnerabilities. Right off the bat, we have two structs: data which has a character array of 64 bytes, and fp which has a pointer to a function.
Next we have two functions winner() and nowinner(), each of which will print out different results. In the main() function, we allocate memory to d and f on the heap, we then set fp of f to the function nowinner. We print some information about the pointers, and then copy the data from the first argument passed to the program into the buffer of d. Lastly, we call the function that fp was set to.
Now if you’ve got a keen eye, you might have already spotted the developer’s mistake. If you didn’t, it’s explained in the next section.
An exploitation example
Now when exploiting a program, it almost goes without saying, but the first thing to do is run it. We’ve seen the code, but let’s see the program in action as it will help us in the next steps.

Running the program
If we first run the program without arguments, it throws a segfault. If we run it with a single argument it outputs “level not passed”, and if we give it a second argument it ignores it. So what’s happening on the heap?

This is what the heap looks like in the different scenarios
This image provides us a look at the heap with these given inputs. Since in the first run we don’t provide an input it is empty, so when strcpy is called it points to nothing and thus a segmentation fault occurs. In the second scenario, strcpy successfully copies the first argument given to the program, which is argv[1]. argv[2] is never used as the second argument is just ignored by the program.
Luckily we’ve read the code and know that the first argument is being passed to an unchecked buffer of 64 bytes, so we start by giving it 64 characters and see what happens:

Fuzzing the input of the program
I originally started inputting letters from A to N since I’m doing four of each character (which will display as hex and is easy to identify where in the string something is going wrong). I kept adding characters from the alphabet until finally it threw a segfault at “T”, making the inputted data a total of 80 characters, despite the buffer only having a limit of 64. This normally happens due to protections introduced by the compiler.
I added some “U”s to see what would happen and it seemed the segfault address changed. That’s a bit strange. To double check, I tried entering a single “U” and it still added a 55 to the segfault address (0x55 in ASCII is “U”). Seeing as this is the point where it is overwriting the addresses, we’ll mark it down as important.
Something else that we notice is the segfault is only raised after the program has printed the data about the struct pointers. We also notice that it stopped printing “level not passed”. Thus we can conclude that the memory space that the “T”s and “U”s are taking up are corrupting the address to which fp is pointing.
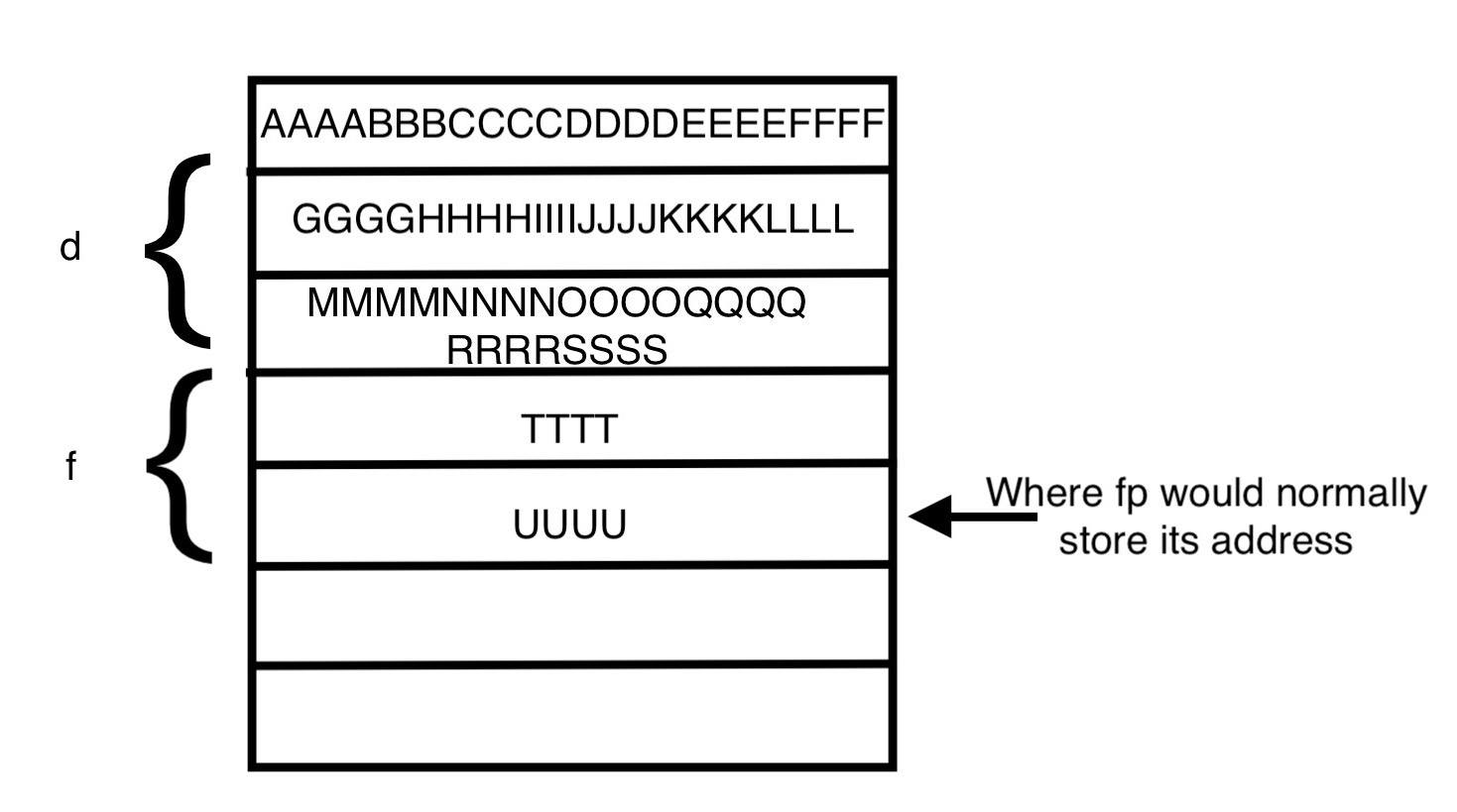
What the heap looks like now that the buffer is overflowed
As we can see in the image above, characters overflow from the buffer of the first struct into the memory addresses of the second struct. If we look at the memory image below we can see each chunk contains some information at the beginning of the block of memory before the actual data:

A malloc as it appears on the heap, from here
The reason the segfault occurs when we get to the “T”‘s is because we are overwriting the information at the beginning of the block. We can now mess around with the heap since we’re leaking the memory and get it to output different results.
Seeing as the character “U” changes the segfault address, I’ll replace those characters with our winner() address. Now if this was done in the wild an attacker would place the address of their malicious code here. Let’s see where the winner() function is located. By doing disass winner gdb will disassemble the function and print the address of the first instruction. Let’s go ahead and overwrite the “U” with the hex address of the first instruction in the winner() function.

Exploiting the program
Now we can see that I ran the function for the address a little bit differently. In order to pass the hex address we need to insert it using echo -ne. To pass the command, we need to use backticks so we open the string, enclose it in backticks, and pass the echo command our custom string. We separate each hex byte with “” to identify it as hex. Lastly, the reason we write the address back to front is because it works in little endian notation. Knowing which endianness to use is always important when exploiting a function, in this case I tried little endian on my first time and it worked.
Conclusion
This was a very basic step into the world of heap overflows, and serves as a stepping stone to the future of this blog series where we will see more advanced heap exploits. It is important that we understand how the heap works first, hence why I started with something similar to a traditional stack buffer overflow.
For our latest research, and for links and comments on other research, follow our Cyber Lab on Twitter.